
The Impact and Future of ChatGPT
What really powerful foundation models and generative models mean for AI researchers, tech, and the world at large.

Introduction

It’s been a couple of months since OpenAI released ChatGPT, the large language model chatbot that not only blew the minds of many AI researchers but also introduced the power of AI to the general public. Briefly, ChatGPT is a chatbot that can respond to human instructions to do tasks from writing essays and poems to explaining and debugging code. The chatbot displays impressive reasoning capabilities and performs significantly better than prior language models.
In this editorial, I will discuss my personal takes on ChatGPT’s impact on three groups of people: AI researchers, Tech developers, and the general public. Throughout the piece, I will speculate on the implications of technologies like ChatGPT and outline some scenarios that I believe are likely to happen. This article leans more toward an op-ed than a fact-based report, so take these views with a grain of salt. With that, let’s dive in…
ChatGPT for AI Researchers
To me, a fellow AI researcher, the most important lesson of ChatGPT is that curating human feedback is very important for improving the performance of large language models (LLMs). ChatGPT changed my, and I suspect, many researchers’ views on the problem of AI alignment for LLMs, which I’ll explain now.
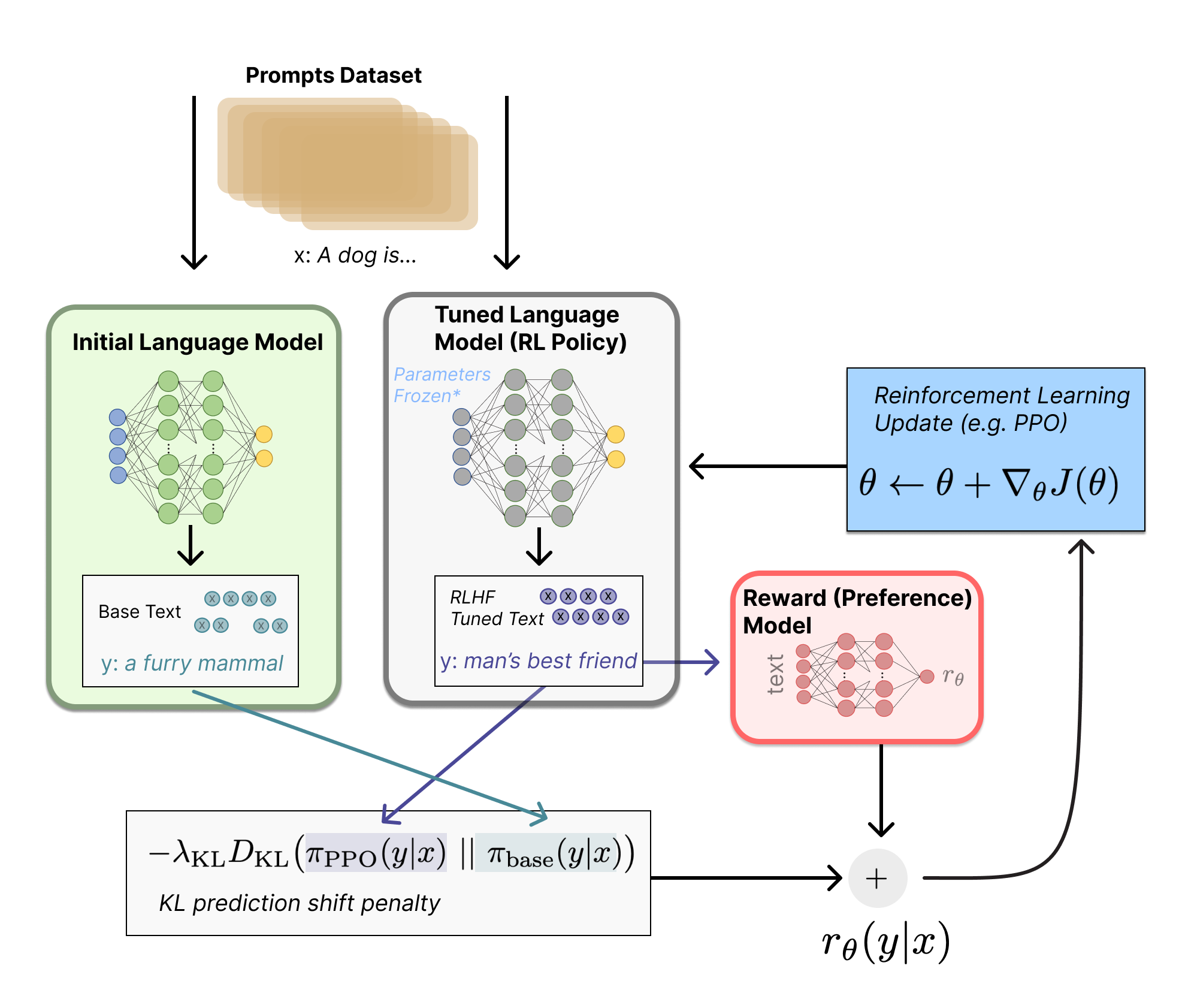
Before ChatGPT I intuitively thought that we had two different problems when it comes to LLMs: 1) improving LLMs’ performance on certain language-based tasks (e.g. summarization, question and answering, multi-step reasoning) while 2) avoiding harmful/toxic/biased text generations. I thought of these two objectives as related but separate and called the second problem the alignment problem. I learned from ChatGPT that alignment and task performance are really the same problem, and aligning LLMs’ outputs with human intent both reduced harmful content as well as improved task performance.
For a bit of context, on a very high level, one can think of separating modern LLM training into 2 steps:
Step 1: Self-Supervised Learning (SSL) of a neural network model to predict the next word (token) given a sequence of previous words (tokens) - this is trained on a very large, Internet-scale dataset.
Step 2: Aligning the LLMs’ generations with human preferences through various techniques, like fine-tuning the LLM on a small dataset of high-quality instruction-following texts and using Reinforcement Learning to fine-tune the LLM with a learned reward model that predicts human preferences.
For ChatGPT, OpenAI likely used many different techniques in tandem with each other to produce the final model. It also seemed like OpenAI was able to quickly respond to online complaints of misaligned behaviors (e.g. generating harmful texts), sometimes in days if not hours, so the company must also have ways of modifying/filtering model generations without actually retraining/fine-tuning the model.
ChatGPT marks a quiet come-back for Reinforcement Learning (RL). Briefly, Reinforcement Learning with Human Feedback (RHLF) first trains a reward model that predicts how high a human would score a particular LLM generation, then it uses this reward model to improve the LLM through RL.
I won’t go into too much in detail about RL here, but OpenAI has traditionally been known for its RL prowess, having authored OpenAI gym which jump-started RL research, trained RL agents to play DoTA, and famously trained robots to play the Rubik’s cube using RL on millions of years of simulation data. After OpenAI disbanded its robotics team, it seemed like RL was fading into the background for OpenAI, as its achievements in generative models came mostly from Self-Supervised Learning. The success of ChatGPT, which hinges upon RLHF, is bringing new attention to RL as a practical method for improving LLMs.
