
Last Week in AI #328 - DeepSeek 3.2, Mistral 3, Trainium3, Runway Gen-4.5
DeepSeek Releases New Reasoning Models, Mistral closes in on Big AI rivals with new open-weight frontier and small models, and more!

DeepSeek Releases New Reasoning Models to Match GPT-5, Rival Gemini 3 Pro
Related:
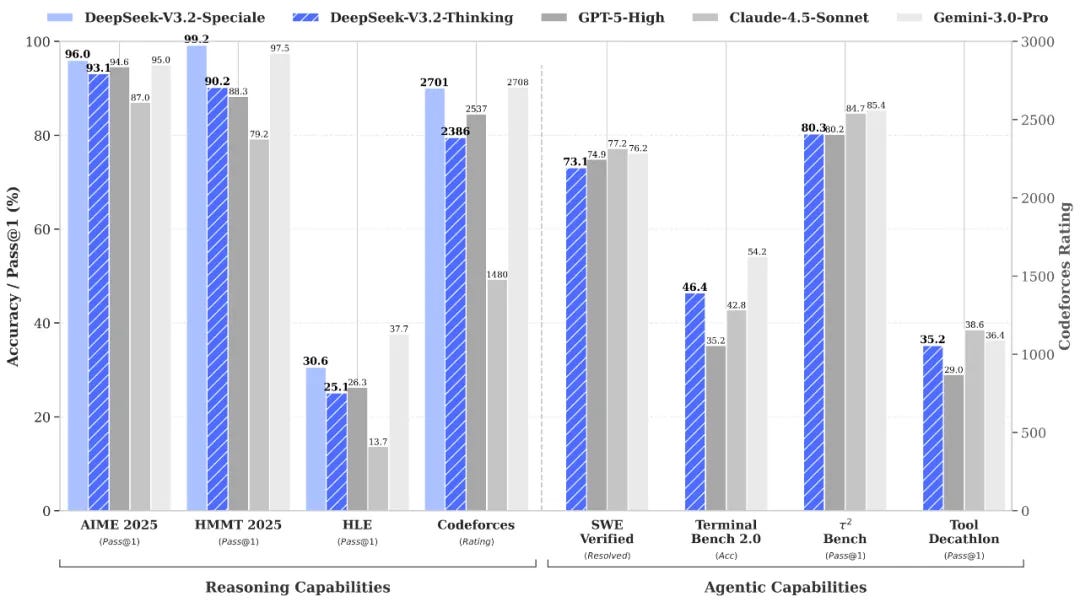
DeepSeek released two open-source reasoning-first models, DeepSeek-V3.2 and DeepSeek-V3.2-Speciale, on Hugging Face, with V3.2 live across its app, …
