

The Inherent Limitations of GPT-3
The Inherent Limitations of GPT-3
On why GPT-3 as is will not cost many people their jobs or soon lead to AGI

In my last editorial, I went over the fact that GPT-3 was a big deal and caused a large stir in the world of AI. Some thought it such a big deal as to worry about losing jobs and career paths in a post GPT-3 world, and many thought it to be a major leap towards the goal of AGI. But, as Skynet Today covered at the time of its release, much of the hype surrounding GPT-3 was excessive and overestimated its capabilities. This was not a novel position; OpenAI’s CEO at the time said as much:
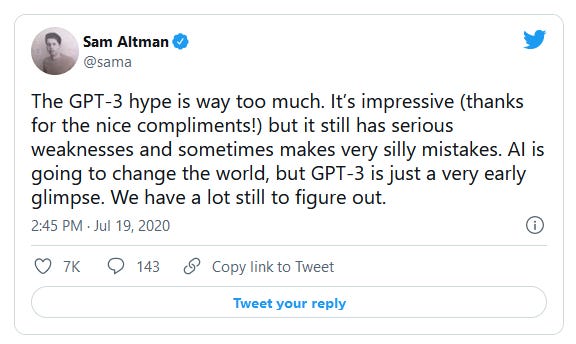
Others have already pointed out the various limitations of GPT-3 that mean people may not need to worry so, and my aim with this piece is to recap and explain these limitations more fully and succinctly than other articles have. These limitations may of course be addressed in future iterations of GPT, but none are trivial -- and some are very challenging -- to fix. They also apply to any models similar to GPT-3, and I only address GPT-3 in particular as it is the most well known and most discussed instance of such models. With that being said, let us go on to its list of limitations.
First, and most obviously, GPT-3 deals only with text. After all, it is a language model. The most exciting aspect of it is that it proved to be able to do a large variety of tasks that involve text. But text alone is clearly not that general; a huge part of what humans do involves images, video, audio, and other sorts of data. And as we shall see, GPT-3 has further limitations that limit many things it can do with text, as well.

The next most obvious and most significant limitation is that GPT-3 has limited input and output sizes. It can take in and output 2048 linguistic tokens, or about 1500 words. That’s a substantial number of words and more than past iterations of GPT, but still quite limited. There are workarounds for this, but research on it is still in its early stages. Likewise, GPT-3 lacks any form of memory. In other words, it cannot remember inputs it has seen or outputs it has produced in the past.
These past two limitations already demonstrate that GPT-3 inherently cannot do many text-related tasks. Much has been said about its potential to put many programmers out of a job, but such jobs typically require knowing a large amount of context with respect to the need and goal of the project. With its limited input-size and output-size, GPT-3 would not be able to absorb all this context or output code that leverages this context without human aid. And with its lack of memory, GPT-3 would not be able to take part in iterative development that requires awareness of past developments.
Of course, the job of programming will likely evolve with the introduction of the GPT-3 based GitHub CoPilot, but this is a long way from costing people their jobs. Many other examples of tasks that are likewise made impossible (or at least hard) by these limitations exist: writing novels or other long documents, engaging in ongoing conversations, understanding long email threads, etc.
Next, we get to a subtler but still important limitation: GPT-3 lacks reliability and interpretability. That is, it can be hard to guarantee that its outputs will always be acceptable, and hard to know why it is the case when its outputs are not acceptable. This makes it unusable in contexts where even an incorrect output in 1 case out of a 100 is unacceptable. The GPT-3 paper makes this point as well:
“GPT-3 shares some limitations common to most deep learning systems – its decisions are not easily interpretable, it is not necessarily well-calibrated in its predictions on novel inputs as observed by the much higher variance in performance than humans on standard benchmarks, and it retains the biases of the data it has been trained on. This last issue – biases in the data that may lead the model to generate stereotyped or prejudiced content – is of special concern from a societal perspective, and will be discussed along with other issues in the next section on Broader Impacts”
Again, much research is focused on addressing this issue, and again, it is still in its early stages. Biases aside, it can often output things that are only subtly flawed or untrue, which is even worse. Again going back to the case of programmers, an essential part of the job is debugging, and this may be made harder when these bugs are introduced by an AI. Even writing essays with GPT-3 is a questionable idea, as it can often output text that is plausible but also utterly incorrect:

On to a more minor but still important limitation: GPT-3 is slow to both run and train. Its sheer size makes it so it can take a second or more for it to produce an output. This is not an issue for all applications, but it is for many. Again, this is noted in the GPT-3 paper:
“A limitation associated with models at the scale of GPT-3, regardless of objective function or algorithm, is that they are both expensive and inconvenient to perform inference on, which may present a challenge for practical applicability of models of this scale in their current form.”
Moreover, training it can take weeks or months even with powerful computing clusters. A crucial aspect of using machine learning models in production is to do so in an iterative manner with continuous re-training of the model, which is of course hard to do if training takes that long.
Lastly, GPT-3 has a host of other technical limitations, many of which are outlined in the paper:
“GPT-3 has several structural and algorithmic limitations
…
A more fundamental limitation of the general approach described in this paper – scaling up any LM-like model, whether autoregressive or bidirectional – is that it may eventually run into (or could already be running into) the limits of the pretraining objective.
…
Another limitation broadly shared by language models is poor sample efficiency during pre-training. While GPT-3 takes a step towards test-time sample efficiency closer to that of humans (one-shot or zero-shot), it still sees much more text during pre-training than a human sees in their lifetime.”
To summarize, GPT-3 has many limitations that constrain its capabilities, and these limitations are important to be aware of when predicting its potential impact on your career or the future in general. That is not to say that GPT-3 is not a major milestone in AI research -- in my opinion it very much is. It has already led to the formation of many startups as well as GitHub CoPilot, and so its impact will likely be considerable. As with any major scientific development, it’s great to be excited about as long as you don’t get carried away and recognize there is still a long and winding road ahead, with this development being but a step on that road.
About the Author:
Andrey Kurenkov (@andrey_kurenkov) is a PhD student with the Stanford Vision and Learning Lab working on learning techniques for robotic manipulation and search. He is advised by Silvio Savarese and Jeannette Bohg.